

Every year, conservation biologists try to answer the same fundamental question: how many animals are actually out there? That baseline number determines everything. It decides whether a species gets listed as endangered, whether a habitat corridor is worth fighting for, and whether a recovery plan is actually working.
For decades, the answer came from traditional mark-recapture methods: catch an animal, tag it physically, release it, and count how many tagged individuals show up again later. While it served ecology well for a time, physical tagging has massive bottlenecks. It requires intense field permits, expensive equipment, trained handlers, and often animal sedation.
Worse, for some species like whale sharks, physical tags simply fall off, foul, or never get re-sighted. Re-sighting rates below 1% are not unusual.
But what if the animal could work as its own tag?
That is the premise behind mark re-ID (mark re-identification), the process of replacing physical tags with an animal's natural, unique biometrics using computer vision.
Most animals carry natural markings that are completely distinctive and stable over time. Think of the spot pattern on a whale shark’s flank, the unique notches along a dolphin’s dorsal fin, a zebra’s stripe arrangement, or even the whisker patterns of a lion.
In computational ecology, mark re-ID treats these natural patterns as organic barcodes. The workflow is entirely non-invasive:
1. A researcher or citizen scientist photographs an animal in the wild.
2. An AI-driven computer vision system analyzes the image.
3. The software compares the distinct markings against a digital catalog of previously photographed individuals.
If the system finds a match, it’s a "recapture", statistically identical to recovering a tagged animal, but achieved without ever touching or stressing the creature.
The outputs feed directly into the analytical software conservation biologists already rely on, such as Program MARK, SOCPROG, or GenAlEx. The underlying population mathematics haven't changed, but AI has changed how we read the marks.
Biologists have matched individual whales by their fluke patterns for decades. Historically, however, this was done entirely by eye, one photograph at a time.
The backlog problem was crippling. A small team of researchers can only squint at photo arrays for so many hours before fatigue sets in and human error takes over.
This is where Wildbook, an open-source software platform engineered by our Wild Me team, transforms the discipline.
During an early, large-scale deployment in Nairobi National Park, volunteers across 27 vehicles used 55 cameras to collect nearly 10,000 photographs of plains zebras and Masai giraffes in just two days. Processing that volume of data by hand would have taken a room of experts months of tedious labor.
With Wildbook’s AI pipeline, it took a fraction of the time. The resulting data fed directly into IUCN Red List assessments and population models that dictate actual international conservation policy.
The Non-Invasive Advantage: Beyond speed, eliminating physical contact means no darting, no handling stress, and fewer bureaucratic hurdles. For highly sensitive or critically endangered species, going hands-off is often what determines whether a research study gets approved at all.
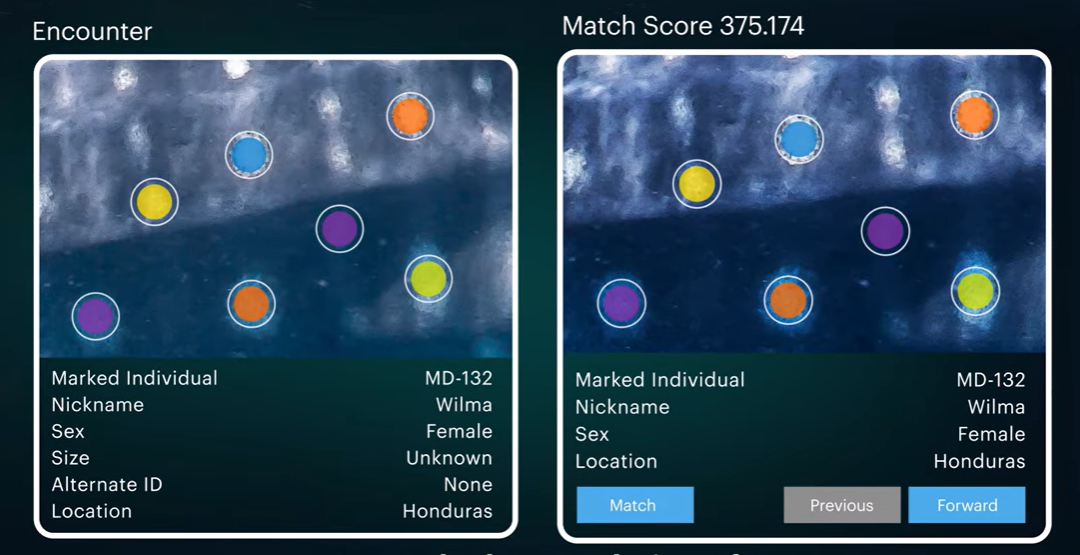
While the user experience is seamless, the engineering behind a machine learning wildlife tracking pipeline involves a multi-stage computer vision process.
1. Object Detection: First, the system must locate the animal within the frame. Using standard object detection models trained on millions of annotated wildlife images, the AI draws a bounding box around the animal and verifies the species.
2. Feature Extraction: Next, the algorithm isolates the specific visual features that make that species distinct. Depending on the animal, it might map spot coordinates, trace a fin outline, or calculate stripe geometry while normalizing for the angle of the photo or lighting conditions.
3. Database Matching: The extracted features are run against a regional or global catalog of known individuals. The AI ranks potential matches by likelihood.
4. Human-in-the-Loop Verification: Finally, a human researcher reviews the top AI-generated recommendations to confirm or correct the result. A confirmed match updates that specific animal’s sighting history, while a non-match prompts the creation of a brand-new individual profile.
The origin story of modern computer vision in wildlife tracking is uniquely cross-disciplinary.
In 2002, diver and programmer Jason Holmberg, now our Chief Data Officer, encountered whale sharks being tracked with traditional plastic spear-tags off the coast of Djibouti. Shocked by the abysmal 1% re-sighting rate, he teamed up with an astrophysicist to adapt an algorithm originally built for the Hubble Space Telescope.
Published by Edward Groth in 1986, the algorithm matched star coordinates by forming triangles from point triplets to identify geometrically similar pairs in deep space. Because a whale shark’s coat mirrors a star field (in Madagascar, they are fittingly called marokintana, meaning "many stars"), Jason mapped the shark's spots instead of constellations.
That modified Groth algorithm became the foundational seed for Wildbook. Today, however, a single algorithm isn’t enough. For example, a snow leopard’s rosettes don't behave like a whale shark's spots, and a zebra's moving stripes require a completely different mathematical approach.
To solve this, we maintain a diverse toolkit of algorithmic approaches:
- The Groth Algorithm: Still highly effective for distinct, rigid spot patterns like whale sharks.
- HotSpotter: A SIFT-based (Scale-Invariant Feature Transform) algorithm that analyzes textures. It is incredibly valuable for new projects because it can match individuals without needing thousands of prior images to train a deep learning model.
- PIE & MiewID: Modern deep learning systems that train the AI to understand what makes individuals visually distinct from one another, rather than just memorizing a fixed list of known animals.
This flexibility allows Wildbook to scale across dozens of distinct species. The same core framework can instantly adapt to support specialized platforms for marine life, cetaceans, or big cats, proving that a unified computational ecology platform can protect wildly diverse ecosystems.
Mark re-ID hasn't changed the core goals of population biology. Researchers still need to calculate survival rates, track migration corridors, and monitor population shifts.
What it has changed is the scale of what is possible.
By pairing automated individual identification with smart field hardware, like our Sentinel, which can run lightweight AI models right at the camera trap—we are moving toward a future where wildlife monitoring happens in near-real-time
A small team with a camera network, or a community of passionate citizen scientists uploading vacation photos, can now protect species that were logistically impossible to study a decade ago. In the midst of a biodiversity crisis, being able to capture and process data this efficiently—and at scale—is a major conservation victory.